
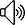
分類(Classification)與回歸都屬于監督學習,兩者的唯一區別在于,前者要預測的輸出變量\(y\)只能取離散值,而后者的輸出變量是連續的。這些離散的輸出變量在分類問題中通常稱之為標簽(Label)。
線性回歸的策略同樣也適用于分類嗎?答案是否定的。下面結合例子簡要說明理由。假設我們現在的任務是根據腫瘤大小判斷是否為良性腫瘤,答案當然只有yes或no。我們用\(y=1\)表示良性腫瘤,用\(y=0\)表示惡性腫瘤。當然,如果你想用其他兩個不同的值分別對應這兩類腫瘤也是可以的。在下圖所示的例子中,我們都使用線性回歸的方式進行分類。在左圖中,如果樣本對應的輸出值小于\(0.5\),我們視其為惡性腫瘤,否則為良性腫瘤,分類效果還不錯;在右圖中,良性腫瘤的大小范圍變廣了一些,線性模型要發生偏轉,如果仍然用\(0.5\)作為分類的閾值(Threshold),誤分類的樣本所占比例就不少了。另外一方面,該分類問題中\(y\)只能取0或1兩種值,而線性模型預測的值去可以遠大于1或遠小于0,極大地偏離輸出變量的值。因此,我們認為用線性回歸解決分類問題是不明智的。

|

|
接下來,我們以二分類為基礎展開討論。樣本標簽\(y\in\{0,1\}\),標簽為1的樣本稱為正樣本(Positive Samples),標簽為0的樣本稱為負樣本(Negative Samples)。我們希望假設函數\(h_\theta(x)\in[0,1]\),選用logistic函數。下圖為logistic函數曲線圖,定義域為\((-\infty,+\infty)\),在整個定義域上都連續可導,其一階偏導如下:
\begin{align}g'(z)&=\fractjgufvlx2j{dz}\frac{1}{1+e^{-z}}\\&=-\frac{1}{(1+e^{-z})^2}\cdot \frac{d(1+e^{-z})}{dz}\\&=\frac{e^{-z}}{(1+e^{-z})^2}\\&=\frac{1}{1+e^{-z}}\cdot\left(1-\frac{1}{1+e^{-z}}\right)\\&=g(z)(1-g(z))\end{align}

我們的假設函數形式如下:
\begin{equation}h_\theta(x)=g(\theta^Tx)=\frac{1}{1+\exp(-\theta^Tx)}\end{equation}
假設分類問題中的后驗概率(posterior probability)形式如下:
\begin{equation}P(y=1|x;\theta)=h_\theta(x)\end{equation}
\begin{equation}P(y=0|x;\theta)=1-h_\theta(x)\end{equation}
綜合公式(7)和公式(8),用更緊湊的形式表述:
\begin{equation}P(y|x;\theta)=h_\theta(x)^y(1-h_\theta(x))^{1-y}\end{equation}
假設所有樣本相互獨立,則似然函數為:\begin{align}L(\theta)&=P(\vec{y}|X;\theta)\\&=\prod_{i=1}^mP(y^{(i)}|x^{(i)};\theta)\\&=\prod_{i=1}^m(h_\theta(x^{(i)})^{y^{(i)}}(1-h_\theta(x^{(i)}))^{1-y^{(i)}}\end{align}
將公式(13)轉換為對數似然函數的形式:
\begin{equation}\ell(\theta)=\log L(\theta)=\sum_{i=1}^m y^{(i)}\log h_\theta(x^{(i)})+(1-y^{(i)})\log(1-h_\theta(x^{(i)}))\end{equation}
對數似然函數\(\ell(\theta)\)對參數\(\theta\)求導:
\begin{equation}
\begin{array}{ll}
&\quad\frac{\partial\ell(\theta)}{\partial \theta_i}\\
&=\sum_{j=1}^m\left(y^{(j)}\frac{1}{g(\theta^Tx^{(j)})}-(1-y^{(j)})\frac{1}{1-g(\theta^Tx^{(j)})}\right)\\
&\quad\cdot\frac{\partial}{\partial\theta_i}g(\theta^Tx^{(j)})\\
&=\sum_{j=1}^m\left(y^{(j)}\frac{1}{g(\theta^Tx^{(j)})}-(1-y^{(j)})\frac{1}{1-g(\theta^Tx^{(j)})}\right)\\
&\quad\cdot g(\theta^Tx^{(j)})(1-g(\theta^Tx^{(j)}))\frac{\partial}{\partial\theta_i}\theta^Tx^{(j)}\\
&=\sum_{j=1}^m\left(y^{(j)}(1-g(\theta^Tx^{(j)})-(1-y^{(j)})g(\theta^Tx^{(j)})\right)x_i^{(j)}\\ &=\sum_{j=1}^m(y^{(j)}-h_\theta(x^{(j)}))x_i^{(j)}
\end{array}
\end{equation}
最后,我們可以采用梯度上升(Gradient Ascend)的策略迭代更新參數\(\theta\),以使對數似然函數收斂到最大值,更新規則如下:
\begin{equation}\theta_i=\theta_i+\alpha\sum_{j=1}^m(y^{(j)}-h_\theta(x^{(j)}))x_i^{(j)}\end{equation}
我在數據集 ionosphere 上做了實驗, 實驗代碼在這里下載 。該數據集一共有351個樣本,每個樣本有35個屬性,其中第35個屬性為'b'或'g'(表示bad或good),是一個二分類問題。我將整個數據集抽取7成作為訓練集,剩下的作為測試集,最終得到的正確率為\(91.509\%\)。代碼中有兩點要說明:1)代碼中實際上還考慮了對參數\(\theta\)正則化處理,避免某些參數過大,我們將LGClassifier.m中的lambda設置為0即可屏蔽正則項,在lambda=0.1時,正確率是會有提升的;2)本文中的目標函數是求使似然函數最大的參數,但是我們利用的LBFGS工具包只針對使目標函數最小的優化,我們只需要在文中的目標函數前面添加負號即可將最大化問題等價轉化為最小化問題;最后,在針對參數\(\theta\)求倒數的時候,也需要在前面添加負號。
更多文章、技術交流、商務合作、聯系博主
微信掃碼或搜索:z360901061

微信掃一掃加我為好友
QQ號聯系: 360901061
您的支持是博主寫作最大的動力,如果您喜歡我的文章,感覺我的文章對您有幫助,請用微信掃描下面二維碼支持博主2元、5元、10元、20元等您想捐的金額吧,狠狠點擊下面給點支持吧,站長非常感激您!手機微信長按不能支付解決辦法:請將微信支付二維碼保存到相冊,切換到微信,然后點擊微信右上角掃一掃功能,選擇支付二維碼完成支付。
【本文對您有幫助就好】元
